var React = require('react');
var HtmlToReactParser = require('html-to-react').Parser;
var htmlInput = '<div><h1>Title</h1><p>A paragraph</p></div>';
var htmlToReactParser = new HtmlToReactParser();
// Turn HTML into a bona fide React component that we can integrate into our React tree
var reactComponent = htmlToReactParser.parse(htmlInput);Tag: Conference
Posts
read more
PromCon 2025
Another year, another PromCon! During PromCon EU 2025, which took place in Munich October 21-22, I shared a talk with my colleague Owen Williams.
Together we talked about the improvements that have gone into Prometheus' OpenTelemetry (AKA OTel) functionalities since PromCon 2024. Significant improvements have been made, both on the functional and the performance side of things.
Some of the points from our talk:
-
Translation of metric and label names in the OTLP endpoint is now optional
-
OpenTelemetry scope metadata can now be included as metric labels
-
Initial support for delta temporality metrics is now available
-
OpenTelemetry non-exponential histograms can now be converted into native histograms with custom buckets
Posts
read more
PromCon 2024
This year marks my debut as conference speaker! During PromCon EU 2024, which took place in Berlin September 11-12, I got two occasions to co-speak!
During the first day of the conference, my colleague Jesús Vázquez and I gave the talk Practical OpenTelemetry with Prometheus 3.0, where we shared with the audience all the work we put in towards making Prometheus 3.0 a 1st class OpenTelemetry (AKA OTel) metrics back-end.
Some of the points from our talk:
Tag: Development
Posts
read more
PromCon 2025
Another year, another PromCon! During PromCon EU 2025, which took place in Munich October 21-22, I shared a talk with my colleague Owen Williams.
Together we talked about the improvements that have gone into Prometheus' OpenTelemetry (AKA OTel) functionalities since PromCon 2024. Significant improvements have been made, both on the functional and the performance side of things.
Some of the points from our talk:
-
Translation of metric and label names in the OTLP endpoint is now optional
-
OpenTelemetry scope metadata can now be included as metric labels
-
Initial support for delta temporality metrics is now available
-
OpenTelemetry non-exponential histograms can now be converted into native histograms with custom buckets
Posts
read more
Prometheus Info Function Blog Post
I’ve blogged for the first time for the Prometheus project!
The blog post is about the PromQL function Björn Rabenstein and I authored together: info.
While info is still considered experimental, we recommend it as the best method for including OpenTelemetry resource attributes in Prometheus queries.
Posts
read more
PromCon 2024
This year marks my debut as conference speaker! During PromCon EU 2024, which took place in Berlin September 11-12, I got two occasions to co-speak!
During the first day of the conference, my colleague Jesús Vázquez and I gave the talk Practical OpenTelemetry with Prometheus 3.0, where we shared with the audience all the work we put in towards making Prometheus 3.0 a 1st class OpenTelemetry (AKA OTel) metrics back-end.
Some of the points from our talk:
Posts
read more
Grafana Mimir Launched
I am very happy to be able to share with the world what I have been working on since July last year: Grafana Mimir! Grafana Mimir is an open source, horizontally scalable, highly available, multi-tenant, long-term storage for Prometheus. It’s a continuation of the Cortex project, but licensed under AGPL. Please see the launch post for the details!
Posts
read more
An Example Substrate Runtime Module
Substrate is a framework for making custom blockchains, made available by Berlin based Parity Technologies, who are until now the best known for making the second-most popular (after the official one, Go Ethereum) client for the Ethereum blockchain, also called Parity. Parity Technologies is led by Gavin Wood, one of the inventors of Ethereum and as such one of the true authorities in the blockchain space.
Based on their significant experience in developing the Ethereum blockchain, Parity devised Substrate as a framework/toolkit for those who wish to design their own blockchains as opposed to having to build on top of e.g. Ethereum, while not having to reinvent all the basic building blocks, such as consensus logic. Like the Parity client, Substrate is written in the Rust language.
Posts
read more
JavaScript/Web Assembly Binding for Indy Crypto
At the behest of the excellent Quorum Control company, I have carried out my first foray into both Rust and Web Assembly (abbr. Wasm), making a JavaScript/Wasm binding of the Hyperledger Indy Crypto library. The reason behind this undertaking is that Quorum Control (and others) need BLS cryptographic signature verification abilities in JavaScript applications (Web and Node.js), and Indy Crypto provides a solid implementation of this although in the Rust language.
Luckily, there are facilities for converting Rust code into Web Assembly, i.e. the wasm-bindgen tool. While still a fledgling project, it allows us to expose a JavaScript API for the BLS module of Indy Crypto. In practice, this is done by writing a set of Rust functions tagged so that they get exported by the binding generated by wasm-bindgen. Additionally, we produce two variants of the binding: One for Node.js and one for ECMAScript modules aware systems (such as the Webpack bundler), in order for it to work both server side and in the browser.
Posts
read more
Experimental Berlin Mentioned in The Guardian
My project Experimental Berlin received a nice mention in British newspaper The Guardian!
Posts
read more
Official Elasticsearch/Fluentd/Kibana Add-On for Kubernetes updated to 5.5
My pull request for updating the official Elasticsearch/Fluentd/Kibana logging add-on for Kubernetes to version 5.5.1 of Elasticsearch and Kibana was recently approved and merged into the master branch! Users of the popular EFK/ELK stack can now enjoy the latest version with their Kubernetes clusters!
Posts
read more
Route Handling Framework for Choo
I’ve made a complementary route handling framework for Yoshua Wuyts' JavaScript SPA (Single Page Application) framework Choo: choo-routehandler. For those unfamiliar with Choo, it’s a view framework similar to React and Marko, although with a strong focus on simplicity and hackability and working directly with the DOM instead of a virtual DOM (unlike React).
Basically, the motivation for making the framework was that I found myself implementing the same pattern in my Choo apps: To load data before rendering a view corresponding to a route and to require authentication before accessing certain routes. I didn’t find any good way to handle this baked into Choo, even though it has a rather good routing system built into it. It was also tricky to use Choo’s standard effects/reducers system to implement handling of route change, since these are asynchronously triggered and I could end up handling the same route change several times as a result.
Posts
read more
Avoiding Popup Blocking when Authenticating with Google
When I recently implemented Google authentication in a Web app, I discovered that I fell victim to the browser’s built-in popup blocking mechanism, which would hide Google’s requisite login dialog. While popup blocking can be pretty good to have in the face of more or less malicious websites and intrusive ads, it’s a real drag when trying to implement something so beneficial, not to say fundamental, as authentication.
At least in the end, I learned something from overcoming this challenge. What I came to realize is that browsers distinguish between (likely) wanted and unwanted popups, by determining whether popups were initiated by user clicks. What this comes down to technically, in programming terms, is that the stackframe opening the popup (via window.open) must be close on the stack to the one handling the click event.
Posts
read more
Event Catalogue for Berlin Released
I’m finally ready to share what I’ve been working on for the last few months, an online catalogue of underground cultural events in the city of Berlin: Experimental Berlin. My best effort to date I think! For this project I’ve been using Yoshua Wuyts' excellent JavaScript framework Choo.
Posts
read more
Maintainership of html-to-react
I’m happy to announce that I’ve taken over maintainership of the popular NPM package html-to-react, which currently has about 3600 downloads per month. This package has the ability to translate HTML markup into a React DOM structure.
An example should give you an idea of what html-to-react brings to the table:
Posts
read more
Achieving Infinite Scrolling with React.js
As part of developing MuzHack I had to implement a method of loading search results on demand, i.e. not everything at once. I decided on the "infinite scrolling" method, which means that as seen on f.ex. Twitter, you load more content as the user scrolls down the page. This is an alternative to the more traditional pagination method, where content (e.g. search results) is partitioned into pages, and the user loads more content by explicitly navigating to another page.
Posts
read more
MuzHack featured in Electronic Beats
Electronic Beats Magazine did a quick writeup on my MuzHack project. Nice that people are paying attention!
Posts
read more
Uploading Files to Amazon S3 Directly from the Web Browser
Amazon S3 is at the time of writing the premier file storage service, and as such an excellent choice for storing files from your Web application. What if I were to tell you these files never need to touch your application servers though?
The thing to be aware of is that the S3 API allows for POST-ing files directly from the user’s Web browser, so with some JavaScript magic you are able to securely upload files from your client side JavaScript code directly to your application’s S3 buckets. The buckets don’t even have to be publicly writeable.
Posts
read more
Zero Downtime Docker Deployment with Tutum
In this post I will detail how to achieve (almost) zero downtime deployment of Docker containers with the Tutum Docker hosting service. Tutum is a service that really simplifies deploying with Docker, and it even has special facilities for enabling zero downtime deployment, i.e. the Tutum team has a version of HAProxy that can switch seamlessly between Docker containers in tandem with Tutum’s API. There is the caveat though, that at the time of writing, there is slight downtime involved with HAProxy’s switching of containers, typically a few seconds. I have been assured though, that this will be improved upon before Tutum goes into General Availability.
Posts
read more
MuzHack - Members Now Able to Advertise Workshops
I am pleased to announce that MuzHack members are now able to inform of their availability for workshops, which to me goes hand in hand with publishing open music hardware, as it allows makers to connect with their audience (and vice versa). It should also allow for more efficient (and enjoyable) sharing of knowledge and skills, as would-be makers get the chance to learn from the experts, and socialize with other enthusiasts.
Posts
 read more
read more
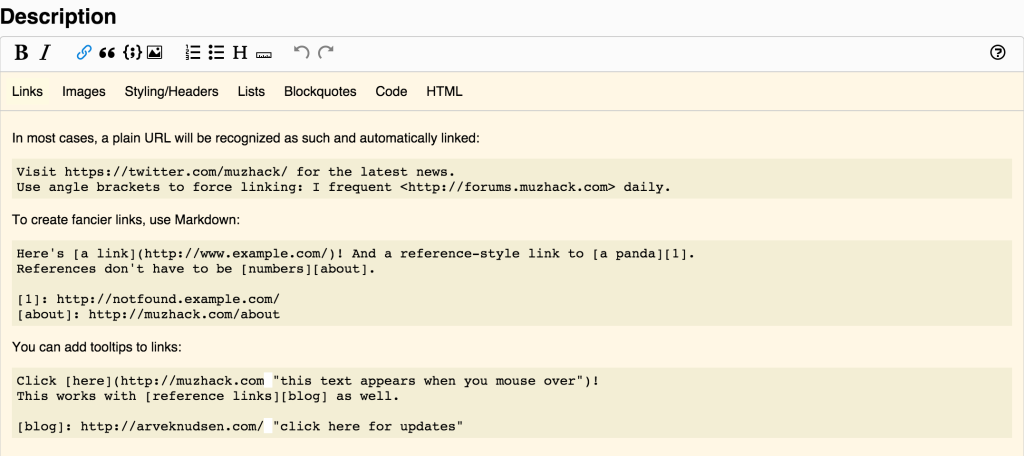
Help Functionality Added to MuzHack's Markdown Editors
The Markdown editors in MuzHack are now sporting a help button, to display documentation about the supported Markdown syntax. Early user feedback suggested this was a much desired feature, as many users aren’t familiar with the Markdown syntax.
Posts
read more
Stack Overflow's Markdown Editor Adapted
Stack Overflow and Markdown
Stack Overflow is a familiar, and cherished, name to many a programmer these days. No wonder, as it is nothing short of an ingenious way of finding answers to the many problems you come across as you’re writing code. Myself I can’t remember the last time I consulted a book on programming, since starting to use SO many years ago. One of the cool things about the site is that you write your questions/answers in the (now ubiquitous) Markdown language, which is a quite readable little language that translates to HTML with support for simple formatting such as italic and bold text, plus, not least, code blocks.
Posts
read more
MuzHack Presentation at Notam
So I gave the first presentation ever on MuzHack today, at the Norwegian sound research centre Notam. Feedback was positive and I got lots of great leads on who I should connect with further, and elsewhere I might present, both nationally and internationally.
Another presentation elsewhere in Norway might be in the works, later this year.
Posts
read more
Meteor: Creating Custom Reactive Data Sources
A core concept in Meteor is reactivity. Basically, this means that Meteor can re-run computational functions automatically whenever their (reactive) data sources change. Typically, this happens without your having to think about it, since you’re using an in-built reactive data source, such as database collections. A typical example of a function needing to react to a data source (e.g. a collection) changing is a template helper, which needs to produce a new value to base the template rendering on.
Posts
read more
Using Papertrail from Docker/Tutum
In my search for a comprehensive logging solution for MuzHack that works in a Dockerized environment, more specifically Tutum, I came across Papertrail.
Papertrail is a fairly simple Web application for log aggregation, that receives log data over the Internet through the syslog protocol. As a registered user of Papertrail, you receive a syslog address that serves as your logging destination. Multiple sources (or "systems" as per Papertrail lingo) can use the same logging destination, as Papertrail will automatically discern between them (based on their hostnames). In my case, this corresponds to my staging and production deployments.
Posts
read more
Calling Trello API from Meteor
I just ported the Trello client API to a Meteor package, in order to be able to authorize my application before making actual API calls from the server side (let’s just avoid the hassle of cross-site scripting).
The following snippet shows my client side flow for creating a Trello board; first I authorize against Trello, then I call a Meteor server method to perform the corresponding Trello REST API call:
Session.set("isWaiting", true)
# MuzHack's Trello app key
Trello.setKey(Meteor.settings.public.trelloKey)
# Have the Trello client lib display a popup wherein the user authorizes MuzHack's read-write access
Trello.authorize({
type: "popup"
name: "MuzHack"
scope: { read: true, "write": true }
success: ->
logger.info("Trello authorization succeeded")
token = Trello.token()
Meteor.call('createTrelloBoard', inputValues.name, inputValues.desc, inputValues.org,
token, (error, result) ->
Session.set("isWaiting", false)
if error?
logger.warn("Server failed to create Trello board:", error)
notificationService.warn("Error",
"Server failed to create Trello board: #{error.reason}.")
else
logger.debug("Server was able to successfully create Trello board")
)
error: ->
logger.warn("Trello authorization failed")
Session.set("isWaiting", false)
})
Posts
read more
How to Back Up Discourse
I’ve recently set up a Discourse forum on DigitalOcean, and was wondering how to implement automatic backups. Turns out Discourse supports both automatic backups and uploading them to S3. Couldn’t be easier!
To save money, you might want to create a lifecycle rule on S3 to archive the backups to Glacier, which is a slower, but cost-efficient, alternative to S3.
Posts
read more
Cloud-Config File for CoreOS with 2 GB of Swap on DigitalOcean
I recently installed Discourse on a CoreOS node at DigitalOcean. Since I chose the minimum spec that Discourse can run on, 1 GB memory, I had to enable 2 GB of swap space. This is solved by configuring CoreOS with an automatic swap service, through the standard cloud-config file. My complete cloud-config file (input this into the node’s user data) looks as follows:
#cloud-config
coreos:
etcd2:
# generate a new token for each unique cluster from https://discovery.etcd.io/new?size=3
# specify the initial size of your cluster with ?size=X
discovery: https://discovery.etcd.io/
# multi-region and multi-cloud deployments need to use $public_ipv4
advertise-client-urls: http://$private_ipv4:2379,http://$private_ipv4:4001
initial-advertise-peer-urls: http://$private_ipv4:2380
# listen on both the official ports and the legacy ports
# legacy ports can be omitted if your application doesn't depend on them
listen-client-urls: http://0.0.0.0:2379,http://0.0.0.0:4001
listen-peer-urls: http://$private_ipv4:2380
units:
- name: etcd2.service
command: start
- name: fleet.service
command: start
- name: swap.service
command: start
content: |
[Unit]
Description=Turn on swap
[Service]
Type=oneshot
Environment="SWAPFILE=/2GiB.swap"
RemainAfterExit=true
ExecStartPre=/bin/bash -c "\
fallocate -l 2G $SWAPFILE && \
chmod 600 $SWAPFILE && \
chattr +C $SWAPFILE && \
mkswap $SWAPFILE && \
losetup -f $SWAPFILE"
ExecStart=/usr/bin/sh -c "/sbin/swapon $(/usr/sbin/losetup -j ${SWAPFILE} | /usr/bin/cut -d : -f 1)"
ExecStop=/usr/bin/sh -c "/sbin/swapoff $(/usr/sbin/losetup -j ${SWAPFILE} | /usr/bin/cut -d : -f 1)"
ExecStopPost=/usr/bin/sh -c "/usr/sbin/losetup -d $(/usr/sbin/losetup -j ${SWAPFILE} | /usr/bin/cut -d : -f 1)"
[Install]
WantedBy=local.target
Posts
read more
MuzHack Is in Production
For some months now I have been developing MuzHack, a platform for makers of music hardware to publish their designs. I’m pleased to say it’s finally in production! The project is in collaboration with the Norwegian music sound research center Notam. My hope is it will spark inspiration between independent hardware developers, similar to how I and so many other software developers have benefitted from GitHub.
Stay tuned for more news!
Posts
read more
Improving Search Result Navigation in the Chromium Developer Console
As detailed in my previous blog post on Adding Support for Regular Expression Search in the Chromium Developer Console, some months ago I set out to make it possible to search for regular expressions in the Chromium/Google Chrome developer console. The task turned out to be more complicated than I anticipated however, and I was asked by the responsible developers to write a separate patch first to improve the console’s search result navigation.
Posts
read more
Building ChucK(JS) with Gradle
As part of my work to port the ChucK music programming language to JavaScript, via the Emscripten C++ to JavaScript compiler, I’ve implemented a Gradle build script for it (instead of the original Makefile). Aside from my working for Gradle, I think it’s a great choice for this kind of polyglot project, where both native and JavaScript targets are built. ChucK is also highly cross platform (i.e. Linux, OS X, Windows), which makes writing a general build script for it demanding. Gradle is a huge help here, especially after its recently gaining support for C and C++.
Posts
read more
How to Access Real DOM Nodes with Mercury/Virtual-DOM, Part 2
In the time since my first post on accessing non-virtual DOM nodes with Mercury / virtual-dom, I’ve learnt that my approach wasn’t as sound as I initially thought. The creator of Mercury, Jake Verbaten, let me know that virtual-dom hooks should only modify node attributes, otherwise the behaviour will be undefined ("innerHTML in hooks breaks the tree indexing that virtual-dom is using").
Instead, I learnt, one should use Mercury Widgets to render directly to the DOM. These aren’t subject to the same restrictions, so it turns out I should’ve been writing widgets instead of hooks.
Posts
read more
Uploading Resized Pictures to S3 in Meteor Application
I am facing the need to upload pictures to Amazon S3 in my Meteor application, MuzHack. The pictures must be resized before storing in S3, and there’s the option of doing this either on my server or in the client. I have elected to go with the latter for now, since it’s simple and doesn’t put load on my server.
To resize pictures client side I am using the Meteor Clientside Image Manipulation library, and to upload pictures to S3 I am using Slingshot.
Posts
read more
How to Access Real DOM Nodes with Mercury/virtual-dom
At work, we are using the Mercury JavaScript UI library, which is a more functional alternative to React (at least this is my understanding of it). It is also highly modular, in that it’s simply composed from several independent libraries (such as virtual-dom).
Like React, Mercury hides the browser DOM behind a virtual model, to improve performance. However, this can cause problems in case you need real access to the DOM. For example, a 3rd party library such as the popular spin.js may require changing the DOM directly, and consequently, the virtual DOM will not suffice.
Posts
read more
Continuous Deployment of MuzHack with Docker on Tutum
I have recently implemented continuous deployment of my MuzHack Web application to the Docker hosting service Tutum, in both production and staging versions. I am really pleased with the smoothness of the whole process of setting it up, and the ease of day-to-day administration.
Docker Image Definition
The very first thing I had to do was to define MuzHack’s Docker image. This is done in the so-called Dockerfile. I base it off the standard Node image. Then I add the PhantomJS headless browser, since it’s required by Meteor (for SEO purposes), and convert MuzHack from a Meteor application into a Node equivalent.
Posts
read more
How to Connect to Meteor's MongoDB Instance from Python
Today I wrote a Python script in order to insert data into Meteor’s MongoDB instance, and the first question that came up was how to get hold of the connection parameters. It turns out that Meteor has a command for this purpose:
meteor mongo -U [site]
If you leave out the 'site' argument, you’ll get the URL to connect to the local MongoDB instance for the current Meteor app (relative to the directory you’re in). The output will look something like mongodb://127.0.0.1:3001/meteor. The final component of the URL is the name of the database ('meteor').
Posts
read more
How to Set Page Title Dynamically with Meteor, Iron Router and SEO
In my Meteor-based project MusitechHub, I recently had to figure out how to set page title dynamically for certain pages. I’m using Iron Router to implement routing in the application, which laid the premise for the solution.
I gathered from the #meteor channel on IRC that I could base my solution on Manuel Schoebel’s SEO package, which is able to set the current page title. Since I wasn’t able to figure out myself how to apply it, I continued by asking on Stack Overflow. Thanks to a helpful answer here, I figured out that I could use Iron Router’s onAfterAction hook to call SEO.set in order to set the title for a certain route/page:
Posts
read more
ChucKJS Talk in Berlin
Last Thursday (the 5th of February) I gave a talk on my project ChucKJS at the Berlin NodeJS meetup. It turned out to be a very positive experience, which is especially great since it was the first time I’ve given a talk at a meetup or indeed outside of internal company gatherings. Based on the number of questions I received, there appeared to be a great deal of interest in Web Audio and Emscripten in the development community. I was even a bit surprised by the amount of questions I received after, but I’ll take this as a sign that at least my talk wasn’t boring ;) I used a Prezi throughout the talk, which I’ve shared here.
Posts
read more
Adding Support for Regular Expression Search in the Chromium Developer Console
Chromium/Google Chrome is my hands-down favourite browser for developing Web sites in, owing to its incredibly sleek developer tools. I feel right at home in its JavaScript console, for evaluating JavaScript interactively or to inspect logs from a running JavaScript application. However, the latter scenario is somewhat let down by the console’s limited search functionality. At the time of writing, the console only lets you search for plain text on a line-by-line basis. If I want to search for regular expressions, which I tend to do, maybe spanning multiple lines, I’ll have to paste the console contents into a text editor (Sublime, anyone?) and search in there.
Tag: Observability
Posts
read more
PromCon 2025
Another year, another PromCon! During PromCon EU 2025, which took place in Munich October 21-22, I shared a talk with my colleague Owen Williams.
Together we talked about the improvements that have gone into Prometheus' OpenTelemetry (AKA OTel) functionalities since PromCon 2024. Significant improvements have been made, both on the functional and the performance side of things.
Some of the points from our talk:
-
Translation of metric and label names in the OTLP endpoint is now optional
-
OpenTelemetry scope metadata can now be included as metric labels
-
Initial support for delta temporality metrics is now available
-
OpenTelemetry non-exponential histograms can now be converted into native histograms with custom buckets
Posts
read more
Prometheus Info Function Blog Post
I’ve blogged for the first time for the Prometheus project!
The blog post is about the PromQL function Björn Rabenstein and I authored together: info.
While info is still considered experimental, we recommend it as the best method for including OpenTelemetry resource attributes in Prometheus queries.
Posts
read more
PromCon 2024
This year marks my debut as conference speaker! During PromCon EU 2024, which took place in Berlin September 11-12, I got two occasions to co-speak!
During the first day of the conference, my colleague Jesús Vázquez and I gave the talk Practical OpenTelemetry with Prometheus 3.0, where we shared with the audience all the work we put in towards making Prometheus 3.0 a 1st class OpenTelemetry (AKA OTel) metrics back-end.
Some of the points from our talk:
Tag: Promcon
Posts
read more
PromCon 2025
Another year, another PromCon! During PromCon EU 2025, which took place in Munich October 21-22, I shared a talk with my colleague Owen Williams.
Together we talked about the improvements that have gone into Prometheus' OpenTelemetry (AKA OTel) functionalities since PromCon 2024. Significant improvements have been made, both on the functional and the performance side of things.
Some of the points from our talk:
-
Translation of metric and label names in the OTLP endpoint is now optional
-
OpenTelemetry scope metadata can now be included as metric labels
-
Initial support for delta temporality metrics is now available
-
OpenTelemetry non-exponential histograms can now be converted into native histograms with custom buckets
Posts
read more
PromCon 2024
This year marks my debut as conference speaker! During PromCon EU 2024, which took place in Berlin September 11-12, I got two occasions to co-speak!
During the first day of the conference, my colleague Jesús Vázquez and I gave the talk Practical OpenTelemetry with Prometheus 3.0, where we shared with the audience all the work we put in towards making Prometheus 3.0 a 1st class OpenTelemetry (AKA OTel) metrics back-end.
Some of the points from our talk:
Tag: Prometheus
Posts
read more
PromCon 2025
Another year, another PromCon! During PromCon EU 2025, which took place in Munich October 21-22, I shared a talk with my colleague Owen Williams.
Together we talked about the improvements that have gone into Prometheus' OpenTelemetry (AKA OTel) functionalities since PromCon 2024. Significant improvements have been made, both on the functional and the performance side of things.
Some of the points from our talk:
-
Translation of metric and label names in the OTLP endpoint is now optional
-
OpenTelemetry scope metadata can now be included as metric labels
-
Initial support for delta temporality metrics is now available
-
OpenTelemetry non-exponential histograms can now be converted into native histograms with custom buckets
Posts
read more
Prometheus Info Function Blog Post
I’ve blogged for the first time for the Prometheus project!
The blog post is about the PromQL function Björn Rabenstein and I authored together: info.
While info is still considered experimental, we recommend it as the best method for including OpenTelemetry resource attributes in Prometheus queries.
Posts
read more
PromCon 2024
This year marks my debut as conference speaker! During PromCon EU 2024, which took place in Berlin September 11-12, I got two occasions to co-speak!
During the first day of the conference, my colleague Jesús Vázquez and I gave the talk Practical OpenTelemetry with Prometheus 3.0, where we shared with the audience all the work we put in towards making Prometheus 3.0 a 1st class OpenTelemetry (AKA OTel) metrics back-end.
Some of the points from our talk:
Tag: Promql
Posts
read more
Prometheus Info Function Blog Post
I’ve blogged for the first time for the Prometheus project!
The blog post is about the PromQL function Björn Rabenstein and I authored together: info.
While info is still considered experimental, we recommend it as the best method for including OpenTelemetry resource attributes in Prometheus queries.
Tag: Grafana-Labs
Posts
read more
Grafana Mimir Launched
I am very happy to be able to share with the world what I have been working on since July last year: Grafana Mimir! Grafana Mimir is an open source, horizontally scalable, highly available, multi-tenant, long-term storage for Prometheus. It’s a continuation of the Cortex project, but licensed under AGPL. Please see the launch post for the details!
Tag: Grafana-Mimir
Posts
read more
Grafana Mimir Launched
I am very happy to be able to share with the world what I have been working on since July last year: Grafana Mimir! Grafana Mimir is an open source, horizontally scalable, highly available, multi-tenant, long-term storage for Prometheus. It’s a continuation of the Cortex project, but licensed under AGPL. Please see the launch post for the details!
Tag: Algorithms
Posts
read more
Practical Networked Applications in Rust, Part 2: Networked Key-Value Store
Welcome to the second installation in my series on taking the Practical Networked Applications in Rust course, kindly provided by the PingCAP company, where you develop a networked and multithreaded/asynchronous key-value store in the amazing Rust language. You may see my previous post in this series here.
In the previous, and initial, post I implemented the course module of making the fundamental key-value store functionality, based around the Bitcask algorithm, which would only allow for local usage on your own computer. In the second module of my course work, I add networking functionality, dividing the application into a client/server architecture so that clients can connect to servers across the network.
Posts
read more
Practical Networked Applications in Rust, Part 1: Non-Networked Key-Value Store
The PingCAP company, makers of the TiDB NewSQL database and the TiKV key-value store, have kindly made publicly available, as well as open-sourced, a set of training courses that they call the "PingCAP Talent Plan". These courses train programmers in writing distributed systems in the Go and Rust languages. They are originally intended by PingCAP to train students, new employees and new contributors to TiDB and TiKV and focus as such on subjects relevant to those projects, but are still appropriate to anyone with an interest in learning to make distributed systems in Go and/or Rust.
Tag: Backend
Posts
read more
Practical Networked Applications in Rust, Part 2: Networked Key-Value Store
Welcome to the second installation in my series on taking the Practical Networked Applications in Rust course, kindly provided by the PingCAP company, where you develop a networked and multithreaded/asynchronous key-value store in the amazing Rust language. You may see my previous post in this series here.
In the previous, and initial, post I implemented the course module of making the fundamental key-value store functionality, based around the Bitcask algorithm, which would only allow for local usage on your own computer. In the second module of my course work, I add networking functionality, dividing the application into a client/server architecture so that clients can connect to servers across the network.
Posts
read more
Practical Networked Applications in Rust, Part 1: Non-Networked Key-Value Store
The PingCAP company, makers of the TiDB NewSQL database and the TiKV key-value store, have kindly made publicly available, as well as open-sourced, a set of training courses that they call the "PingCAP Talent Plan". These courses train programmers in writing distributed systems in the Go and Rust languages. They are originally intended by PingCAP to train students, new employees and new contributors to TiDB and TiKV and focus as such on subjects relevant to those projects, but are still appropriate to anyone with an interest in learning to make distributed systems in Go and/or Rust.
Tag: Database
Posts
read more
Practical Networked Applications in Rust, Part 2: Networked Key-Value Store
Welcome to the second installation in my series on taking the Practical Networked Applications in Rust course, kindly provided by the PingCAP company, where you develop a networked and multithreaded/asynchronous key-value store in the amazing Rust language. You may see my previous post in this series here.
In the previous, and initial, post I implemented the course module of making the fundamental key-value store functionality, based around the Bitcask algorithm, which would only allow for local usage on your own computer. In the second module of my course work, I add networking functionality, dividing the application into a client/server architecture so that clients can connect to servers across the network.
Posts
read more
Practical Networked Applications in Rust, Part 1: Non-Networked Key-Value Store
The PingCAP company, makers of the TiDB NewSQL database and the TiKV key-value store, have kindly made publicly available, as well as open-sourced, a set of training courses that they call the "PingCAP Talent Plan". These courses train programmers in writing distributed systems in the Go and Rust languages. They are originally intended by PingCAP to train students, new employees and new contributors to TiDB and TiKV and focus as such on subjects relevant to those projects, but are still appropriate to anyone with an interest in learning to make distributed systems in Go and/or Rust.
Tag: Networking
Posts
read more
Practical Networked Applications in Rust, Part 2: Networked Key-Value Store
Welcome to the second installation in my series on taking the Practical Networked Applications in Rust course, kindly provided by the PingCAP company, where you develop a networked and multithreaded/asynchronous key-value store in the amazing Rust language. You may see my previous post in this series here.
In the previous, and initial, post I implemented the course module of making the fundamental key-value store functionality, based around the Bitcask algorithm, which would only allow for local usage on your own computer. In the second module of my course work, I add networking functionality, dividing the application into a client/server architecture so that clients can connect to servers across the network.
Tag: Pingcap
Posts
read more
Practical Networked Applications in Rust, Part 2: Networked Key-Value Store
Welcome to the second installation in my series on taking the Practical Networked Applications in Rust course, kindly provided by the PingCAP company, where you develop a networked and multithreaded/asynchronous key-value store in the amazing Rust language. You may see my previous post in this series here.
In the previous, and initial, post I implemented the course module of making the fundamental key-value store functionality, based around the Bitcask algorithm, which would only allow for local usage on your own computer. In the second module of my course work, I add networking functionality, dividing the application into a client/server architecture so that clients can connect to servers across the network.
Posts
read more
Practical Networked Applications in Rust, Part 1: Non-Networked Key-Value Store
The PingCAP company, makers of the TiDB NewSQL database and the TiKV key-value store, have kindly made publicly available, as well as open-sourced, a set of training courses that they call the "PingCAP Talent Plan". These courses train programmers in writing distributed systems in the Go and Rust languages. They are originally intended by PingCAP to train students, new employees and new contributors to TiDB and TiKV and focus as such on subjects relevant to those projects, but are still appropriate to anyone with an interest in learning to make distributed systems in Go and/or Rust.
Tag: Rust
Posts
read more
Practical Networked Applications in Rust, Part 2: Networked Key-Value Store
Welcome to the second installation in my series on taking the Practical Networked Applications in Rust course, kindly provided by the PingCAP company, where you develop a networked and multithreaded/asynchronous key-value store in the amazing Rust language. You may see my previous post in this series here.
In the previous, and initial, post I implemented the course module of making the fundamental key-value store functionality, based around the Bitcask algorithm, which would only allow for local usage on your own computer. In the second module of my course work, I add networking functionality, dividing the application into a client/server architecture so that clients can connect to servers across the network.
Posts
read more
Practical Networked Applications in Rust, Part 1: Non-Networked Key-Value Store
The PingCAP company, makers of the TiDB NewSQL database and the TiKV key-value store, have kindly made publicly available, as well as open-sourced, a set of training courses that they call the "PingCAP Talent Plan". These courses train programmers in writing distributed systems in the Go and Rust languages. They are originally intended by PingCAP to train students, new employees and new contributors to TiDB and TiKV and focus as such on subjects relevant to those projects, but are still appropriate to anyone with an interest in learning to make distributed systems in Go and/or Rust.
Posts
read more
An Example Substrate Runtime Module
Substrate is a framework for making custom blockchains, made available by Berlin based Parity Technologies, who are until now the best known for making the second-most popular (after the official one, Go Ethereum) client for the Ethereum blockchain, also called Parity. Parity Technologies is led by Gavin Wood, one of the inventors of Ethereum and as such one of the true authorities in the blockchain space.
Based on their significant experience in developing the Ethereum blockchain, Parity devised Substrate as a framework/toolkit for those who wish to design their own blockchains as opposed to having to build on top of e.g. Ethereum, while not having to reinvent all the basic building blocks, such as consensus logic. Like the Parity client, Substrate is written in the Rust language.
Posts
read more
JavaScript/Web Assembly Binding for Indy Crypto
At the behest of the excellent Quorum Control company, I have carried out my first foray into both Rust and Web Assembly (abbr. Wasm), making a JavaScript/Wasm binding of the Hyperledger Indy Crypto library. The reason behind this undertaking is that Quorum Control (and others) need BLS cryptographic signature verification abilities in JavaScript applications (Web and Node.js), and Indy Crypto provides a solid implementation of this although in the Rust language.
Luckily, there are facilities for converting Rust code into Web Assembly, i.e. the wasm-bindgen tool. While still a fledgling project, it allows us to expose a JavaScript API for the BLS module of Indy Crypto. In practice, this is done by writing a set of Rust functions tagged so that they get exported by the binding generated by wasm-bindgen. Additionally, we produce two variants of the binding: One for Node.js and one for ECMAScript modules aware systems (such as the Webpack bundler), in order for it to work both server side and in the browser.
Tag: Blockchain
Posts
read more
An Example Substrate Runtime Module
Substrate is a framework for making custom blockchains, made available by Berlin based Parity Technologies, who are until now the best known for making the second-most popular (after the official one, Go Ethereum) client for the Ethereum blockchain, also called Parity. Parity Technologies is led by Gavin Wood, one of the inventors of Ethereum and as such one of the true authorities in the blockchain space.
Based on their significant experience in developing the Ethereum blockchain, Parity devised Substrate as a framework/toolkit for those who wish to design their own blockchains as opposed to having to build on top of e.g. Ethereum, while not having to reinvent all the basic building blocks, such as consensus logic. Like the Parity client, Substrate is written in the Rust language.
Tag: Crypto
Posts
read more
JavaScript/Web Assembly Binding for Indy Crypto
At the behest of the excellent Quorum Control company, I have carried out my first foray into both Rust and Web Assembly (abbr. Wasm), making a JavaScript/Wasm binding of the Hyperledger Indy Crypto library. The reason behind this undertaking is that Quorum Control (and others) need BLS cryptographic signature verification abilities in JavaScript applications (Web and Node.js), and Indy Crypto provides a solid implementation of this although in the Rust language.
Luckily, there are facilities for converting Rust code into Web Assembly, i.e. the wasm-bindgen tool. While still a fledgling project, it allows us to expose a JavaScript API for the BLS module of Indy Crypto. In practice, this is done by writing a set of Rust functions tagged so that they get exported by the binding generated by wasm-bindgen. Additionally, we produce two variants of the binding: One for Node.js and one for ECMAScript modules aware systems (such as the Webpack bundler), in order for it to work both server side and in the browser.
Tag: Javascript
Posts
read more
JavaScript/Web Assembly Binding for Indy Crypto
At the behest of the excellent Quorum Control company, I have carried out my first foray into both Rust and Web Assembly (abbr. Wasm), making a JavaScript/Wasm binding of the Hyperledger Indy Crypto library. The reason behind this undertaking is that Quorum Control (and others) need BLS cryptographic signature verification abilities in JavaScript applications (Web and Node.js), and Indy Crypto provides a solid implementation of this although in the Rust language.
Luckily, there are facilities for converting Rust code into Web Assembly, i.e. the wasm-bindgen tool. While still a fledgling project, it allows us to expose a JavaScript API for the BLS module of Indy Crypto. In practice, this is done by writing a set of Rust functions tagged so that they get exported by the binding generated by wasm-bindgen. Additionally, we produce two variants of the binding: One for Node.js and one for ECMAScript modules aware systems (such as the Webpack bundler), in order for it to work both server side and in the browser.
Posts
read more
Route Handling Framework for Choo
I’ve made a complementary route handling framework for Yoshua Wuyts' JavaScript SPA (Single Page Application) framework Choo: choo-routehandler. For those unfamiliar with Choo, it’s a view framework similar to React and Marko, although with a strong focus on simplicity and hackability and working directly with the DOM instead of a virtual DOM (unlike React).
Basically, the motivation for making the framework was that I found myself implementing the same pattern in my Choo apps: To load data before rendering a view corresponding to a route and to require authentication before accessing certain routes. I didn’t find any good way to handle this baked into Choo, even though it has a rather good routing system built into it. It was also tricky to use Choo’s standard effects/reducers system to implement handling of route change, since these are asynchronously triggered and I could end up handling the same route change several times as a result.
Posts
read more
Avoiding Popup Blocking when Authenticating with Google
When I recently implemented Google authentication in a Web app, I discovered that I fell victim to the browser’s built-in popup blocking mechanism, which would hide Google’s requisite login dialog. While popup blocking can be pretty good to have in the face of more or less malicious websites and intrusive ads, it’s a real drag when trying to implement something so beneficial, not to say fundamental, as authentication.
At least in the end, I learned something from overcoming this challenge. What I came to realize is that browsers distinguish between (likely) wanted and unwanted popups, by determining whether popups were initiated by user clicks. What this comes down to technically, in programming terms, is that the stackframe opening the popup (via window.open) must be close on the stack to the one handling the click event.
Posts
read more
Maintainership of html-to-react
I’m happy to announce that I’ve taken over maintainership of the popular NPM package html-to-react, which currently has about 3600 downloads per month. This package has the ability to translate HTML markup into a React DOM structure.
An example should give you an idea of what html-to-react brings to the table:
var React = require('react');
var HtmlToReactParser = require('html-to-react').Parser;
var htmlInput = '<div><h1>Title</h1><p>A paragraph</p></div>';
var htmlToReactParser = new HtmlToReactParser();
// Turn HTML into a bona fide React component that we can integrate into our React tree
var reactComponent = htmlToReactParser.parse(htmlInput);
Posts
read more
Achieving Infinite Scrolling with React.js
As part of developing MuzHack I had to implement a method of loading search results on demand, i.e. not everything at once. I decided on the "infinite scrolling" method, which means that as seen on f.ex. Twitter, you load more content as the user scrolls down the page. This is an alternative to the more traditional pagination method, where content (e.g. search results) is partitioned into pages, and the user loads more content by explicitly navigating to another page.
Posts
read more
Uploading Files to Amazon S3 Directly from the Web Browser
Amazon S3 is at the time of writing the premier file storage service, and as such an excellent choice for storing files from your Web application. What if I were to tell you these files never need to touch your application servers though?
The thing to be aware of is that the S3 API allows for POST-ing files directly from the user’s Web browser, so with some JavaScript magic you are able to securely upload files from your client side JavaScript code directly to your application’s S3 buckets. The buckets don’t even have to be publicly writeable.
Posts
read more
Stack Overflow's Markdown Editor Adapted
Stack Overflow and Markdown
Stack Overflow is a familiar, and cherished, name to many a programmer these days. No wonder, as it is nothing short of an ingenious way of finding answers to the many problems you come across as you’re writing code. Myself I can’t remember the last time I consulted a book on programming, since starting to use SO many years ago. One of the cool things about the site is that you write your questions/answers in the (now ubiquitous) Markdown language, which is a quite readable little language that translates to HTML with support for simple formatting such as italic and bold text, plus, not least, code blocks.
Posts
read more
Meteor: Creating Custom Reactive Data Sources
A core concept in Meteor is reactivity. Basically, this means that Meteor can re-run computational functions automatically whenever their (reactive) data sources change. Typically, this happens without your having to think about it, since you’re using an in-built reactive data source, such as database collections. A typical example of a function needing to react to a data source (e.g. a collection) changing is a template helper, which needs to produce a new value to base the template rendering on.
Posts
read more
Calling Trello API from Meteor
I just ported the Trello client API to a Meteor package, in order to be able to authorize my application before making actual API calls from the server side (let’s just avoid the hassle of cross-site scripting).
The following snippet shows my client side flow for creating a Trello board; first I authorize against Trello, then I call a Meteor server method to perform the corresponding Trello REST API call:
Session.set("isWaiting", true)
# MuzHack's Trello app key
Trello.setKey(Meteor.settings.public.trelloKey)
# Have the Trello client lib display a popup wherein the user authorizes MuzHack's read-write access
Trello.authorize({
type: "popup"
name: "MuzHack"
scope: { read: true, "write": true }
success: ->
logger.info("Trello authorization succeeded")
token = Trello.token()
Meteor.call('createTrelloBoard', inputValues.name, inputValues.desc, inputValues.org,
token, (error, result) ->
Session.set("isWaiting", false)
if error?
logger.warn("Server failed to create Trello board:", error)
notificationService.warn("Error",
"Server failed to create Trello board: #{error.reason}.")
else
logger.debug("Server was able to successfully create Trello board")
)
error: ->
logger.warn("Trello authorization failed")
Session.set("isWaiting", false)
})
Posts
read more
How to Access Real DOM Nodes with Mercury/Virtual-DOM, Part 2
In the time since my first post on accessing non-virtual DOM nodes with Mercury / virtual-dom, I’ve learnt that my approach wasn’t as sound as I initially thought. The creator of Mercury, Jake Verbaten, let me know that virtual-dom hooks should only modify node attributes, otherwise the behaviour will be undefined ("innerHTML in hooks breaks the tree indexing that virtual-dom is using").
Instead, I learnt, one should use Mercury Widgets to render directly to the DOM. These aren’t subject to the same restrictions, so it turns out I should’ve been writing widgets instead of hooks.
Posts
read more
How to Access Real DOM Nodes with Mercury/virtual-dom
At work, we are using the Mercury JavaScript UI library, which is a more functional alternative to React (at least this is my understanding of it). It is also highly modular, in that it’s simply composed from several independent libraries (such as virtual-dom).
Like React, Mercury hides the browser DOM behind a virtual model, to improve performance. However, this can cause problems in case you need real access to the DOM. For example, a 3rd party library such as the popular spin.js may require changing the DOM directly, and consequently, the virtual DOM will not suffice.
Tag: Wasm
Posts
read more
JavaScript/Web Assembly Binding for Indy Crypto
At the behest of the excellent Quorum Control company, I have carried out my first foray into both Rust and Web Assembly (abbr. Wasm), making a JavaScript/Wasm binding of the Hyperledger Indy Crypto library. The reason behind this undertaking is that Quorum Control (and others) need BLS cryptographic signature verification abilities in JavaScript applications (Web and Node.js), and Indy Crypto provides a solid implementation of this although in the Rust language.
Luckily, there are facilities for converting Rust code into Web Assembly, i.e. the wasm-bindgen tool. While still a fledgling project, it allows us to expose a JavaScript API for the BLS module of Indy Crypto. In practice, this is done by writing a set of Rust functions tagged so that they get exported by the binding generated by wasm-bindgen. Additionally, we produce two variants of the binding: One for Node.js and one for ECMAScript modules aware systems (such as the Webpack bundler), in order for it to work both server side and in the browser.
Tag: Publicity
Posts
read more
Experimental Berlin Mentioned in The Guardian
My project Experimental Berlin received a nice mention in British newspaper The Guardian!
Tag: Kubernetes
Posts
read more
Official Elasticsearch/Fluentd/Kibana Add-On for Kubernetes updated to 5.5
My pull request for updating the official Elasticsearch/Fluentd/Kibana logging add-on for Kubernetes to version 5.5.1 of Elasticsearch and Kibana was recently approved and merged into the master branch! Users of the popular EFK/ELK stack can now enjoy the latest version with their Kubernetes clusters!
Posts
read more
Installing Elasticsearch/Kibana 5.5 within Kubernetes cluster on AWS
In my previous blog post I showed how to use the Kops tool to create a production ready Kubernetes cluster on Amazon Web Services (AWS). In this follow-up post I will show how to install Elasticsearch and its graphical counterpart Kibana in the cluster, in order to be able to collect and store logs from your cluster and search/read them. We will also install Fluentd as this component is responsible for transmitting the standard Kubernetes logs to Elasticsearch. This is generally known as the ELK stack, which stands for Elasticsearch, Logstash (precursor to Fluentd) and Kibana.
Posts
read more
Creating a Highly Available Secured Kubernetes Cluster on AWS with Kops
Today I will be talking about Kops, which is an official tool for creating Kubernetes clusters on AWS, with support for GCE and VMware vSphere in alpha. It takes a whole lot of the pain out of setting up a Kubernetes cluster yourself, but still presents many challenges to overcome and a great degree of freedom in how you configure the cluster.
I have recently created a Kubernetes cluster on AWS for a client, where I used the Kops tool for the very first time and I will here present what I learnt about implementing best practices with this technology stack. Given the rapid development of Kubernetes itself, and how relatively young Kops is, it proved to be far from a walk in the park to create a production-grade cluster. Documentation is often relatively poor, or just plain missing. The intention of this blog post is to make it easier for others going down the same route.
Tag: Aws
Posts
read more
Installing Elasticsearch/Kibana 5.5 within Kubernetes cluster on AWS
In my previous blog post I showed how to use the Kops tool to create a production ready Kubernetes cluster on Amazon Web Services (AWS). In this follow-up post I will show how to install Elasticsearch and its graphical counterpart Kibana in the cluster, in order to be able to collect and store logs from your cluster and search/read them. We will also install Fluentd as this component is responsible for transmitting the standard Kubernetes logs to Elasticsearch. This is generally known as the ELK stack, which stands for Elasticsearch, Logstash (precursor to Fluentd) and Kibana.
Posts
read more
Creating a Highly Available Secured Kubernetes Cluster on AWS with Kops
Today I will be talking about Kops, which is an official tool for creating Kubernetes clusters on AWS, with support for GCE and VMware vSphere in alpha. It takes a whole lot of the pain out of setting up a Kubernetes cluster yourself, but still presents many challenges to overcome and a great degree of freedom in how you configure the cluster.
I have recently created a Kubernetes cluster on AWS for a client, where I used the Kops tool for the very first time and I will here present what I learnt about implementing best practices with this technology stack. Given the rapid development of Kubernetes itself, and how relatively young Kops is, it proved to be far from a walk in the park to create a production-grade cluster. Documentation is often relatively poor, or just plain missing. The intention of this blog post is to make it easier for others going down the same route.
Posts
read more
Zero Downtime Docker Deployment with Amazon ECS
Earlier, I wrote about zero downtime docker deployment with Tutum. I have recently started experimenting with Amazon ECS (EC2 Container Service), which is Amazon’s offering for the orchestration of Docker containers (and thus a competitor to Tutum). I don’t have a lot of experience with ECS yet, but it looks pretty solid so far.
I found there was a real lack of documentation on how to deploy updated Docker images to Amazon, however, and was forced to do some research in order to figure out how it should be done. Through some diligent experimentation of my own with the AWS ECS CLI and not least some valuable help on the Amazon forums, I was able to come up with a script and requirements for the ECS configuration that together lead to streamlined deployment. As it turns out, you even get zero downtime deployment for free (provided that you use an elastic load balancer, mind)! It’s more magical than in the Tutum case, as ECS by default upgrades one node after the other in the background (hidden by the load balancer) so long as it is allowed to take down at least one node as required.
Posts
read more
Uploading Files to Amazon S3 Directly from the Web Browser
Amazon S3 is at the time of writing the premier file storage service, and as such an excellent choice for storing files from your Web application. What if I were to tell you these files never need to touch your application servers though?
The thing to be aware of is that the S3 API allows for POST-ing files directly from the user’s Web browser, so with some JavaScript magic you are able to securely upload files from your client side JavaScript code directly to your application’s S3 buckets. The buckets don’t even have to be publicly writeable.
Posts
read more
How to Back Up Discourse
I’ve recently set up a Discourse forum on DigitalOcean, and was wondering how to implement automatic backups. Turns out Discourse supports both automatic backups and uploading them to S3. Couldn’t be easier!
To save money, you might want to create a lifecycle rule on S3 to archive the backups to Glacier, which is a slower, but cost-efficient, alternative to S3.
Posts
read more
MuzHack Is in Production
For some months now I have been developing MuzHack, a platform for makers of music hardware to publish their designs. I’m pleased to say it’s finally in production! The project is in collaboration with the Norwegian music sound research center Notam. My hope is it will spark inspiration between independent hardware developers, similar to how I and so many other software developers have benefitted from GitHub.
Stay tuned for more news!
Posts
read more
Uploading Resized Pictures to S3 in Meteor Application
I am facing the need to upload pictures to Amazon S3 in my Meteor application, MuzHack. The pictures must be resized before storing in S3, and there’s the option of doing this either on my server or in the client. I have elected to go with the latter for now, since it’s simple and doesn’t put load on my server.
To resize pictures client side I am using the Meteor Clientside Image Manipulation library, and to upload pictures to S3 I am using Slingshot.
Tag: Devops
Posts
read more
Installing Elasticsearch/Kibana 5.5 within Kubernetes cluster on AWS
In my previous blog post I showed how to use the Kops tool to create a production ready Kubernetes cluster on Amazon Web Services (AWS). In this follow-up post I will show how to install Elasticsearch and its graphical counterpart Kibana in the cluster, in order to be able to collect and store logs from your cluster and search/read them. We will also install Fluentd as this component is responsible for transmitting the standard Kubernetes logs to Elasticsearch. This is generally known as the ELK stack, which stands for Elasticsearch, Logstash (precursor to Fluentd) and Kibana.
Posts
read more
Creating a Highly Available Secured Kubernetes Cluster on AWS with Kops
Today I will be talking about Kops, which is an official tool for creating Kubernetes clusters on AWS, with support for GCE and VMware vSphere in alpha. It takes a whole lot of the pain out of setting up a Kubernetes cluster yourself, but still presents many challenges to overcome and a great degree of freedom in how you configure the cluster.
I have recently created a Kubernetes cluster on AWS for a client, where I used the Kops tool for the very first time and I will here present what I learnt about implementing best practices with this technology stack. Given the rapid development of Kubernetes itself, and how relatively young Kops is, it proved to be far from a walk in the park to create a production-grade cluster. Documentation is often relatively poor, or just plain missing. The intention of this blog post is to make it easier for others going down the same route.
Posts
read more
Zero Downtime Docker Deployment with Amazon ECS
Earlier, I wrote about zero downtime docker deployment with Tutum. I have recently started experimenting with Amazon ECS (EC2 Container Service), which is Amazon’s offering for the orchestration of Docker containers (and thus a competitor to Tutum). I don’t have a lot of experience with ECS yet, but it looks pretty solid so far.
I found there was a real lack of documentation on how to deploy updated Docker images to Amazon, however, and was forced to do some research in order to figure out how it should be done. Through some diligent experimentation of my own with the AWS ECS CLI and not least some valuable help on the Amazon forums, I was able to come up with a script and requirements for the ECS configuration that together lead to streamlined deployment. As it turns out, you even get zero downtime deployment for free (provided that you use an elastic load balancer, mind)! It’s more magical than in the Tutum case, as ECS by default upgrades one node after the other in the background (hidden by the load balancer) so long as it is allowed to take down at least one node as required.
Posts
read more
Zero Downtime Docker Deployment with Tutum
In this post I will detail how to achieve (almost) zero downtime deployment of Docker containers with the Tutum Docker hosting service. Tutum is a service that really simplifies deploying with Docker, and it even has special facilities for enabling zero downtime deployment, i.e. the Tutum team has a version of HAProxy that can switch seamlessly between Docker containers in tandem with Tutum’s API. There is the caveat though, that at the time of writing, there is slight downtime involved with HAProxy’s switching of containers, typically a few seconds. I have been assured though, that this will be improved upon before Tutum goes into General Availability.
Posts
read more
Continuous Deployment of MuzHack with Docker on Tutum
I have recently implemented continuous deployment of my MuzHack Web application to the Docker hosting service Tutum, in both production and staging versions. I am really pleased with the smoothness of the whole process of setting it up, and the ease of day-to-day administration.
Docker Image Definition
The very first thing I had to do was to define MuzHack’s Docker image. This is done in the so-called Dockerfile. I base it off the standard Node image. Then I add the PhantomJS headless browser, since it’s required by Meteor (for SEO purposes), and convert MuzHack from a Meteor application into a Node equivalent.
Tag: Choo
Posts
read more
Route Handling Framework for Choo
I’ve made a complementary route handling framework for Yoshua Wuyts' JavaScript SPA (Single Page Application) framework Choo: choo-routehandler. For those unfamiliar with Choo, it’s a view framework similar to React and Marko, although with a strong focus on simplicity and hackability and working directly with the DOM instead of a virtual DOM (unlike React).
Basically, the motivation for making the framework was that I found myself implementing the same pattern in my Choo apps: To load data before rendering a view corresponding to a route and to require authentication before accessing certain routes. I didn’t find any good way to handle this baked into Choo, even though it has a rather good routing system built into it. It was also tricky to use Choo’s standard effects/reducers system to implement handling of route change, since these are asynchronously triggered and I could end up handling the same route change several times as a result.
Tag: Authentication
Posts
read more
Avoiding Popup Blocking when Authenticating with Google
When I recently implemented Google authentication in a Web app, I discovered that I fell victim to the browser’s built-in popup blocking mechanism, which would hide Google’s requisite login dialog. While popup blocking can be pretty good to have in the face of more or less malicious websites and intrusive ads, it’s a real drag when trying to implement something so beneficial, not to say fundamental, as authentication.
At least in the end, I learned something from overcoming this challenge. What I came to realize is that browsers distinguish between (likely) wanted and unwanted popups, by determining whether popups were initiated by user clicks. What this comes down to technically, in programming terms, is that the stackframe opening the popup (via window.open) must be close on the stack to the one handling the click event.
Tag: Google
Posts
read more
Avoiding Popup Blocking when Authenticating with Google
When I recently implemented Google authentication in a Web app, I discovered that I fell victim to the browser’s built-in popup blocking mechanism, which would hide Google’s requisite login dialog. While popup blocking can be pretty good to have in the face of more or less malicious websites and intrusive ads, it’s a real drag when trying to implement something so beneficial, not to say fundamental, as authentication.
At least in the end, I learned something from overcoming this challenge. What I came to realize is that browsers distinguish between (likely) wanted and unwanted popups, by determining whether popups were initiated by user clicks. What this comes down to technically, in programming terms, is that the stackframe opening the popup (via window.open) must be close on the stack to the one handling the click event.
Tag: Experimental-Berlin
Posts
read more
Event Catalogue for Berlin Released
I’m finally ready to share what I’ve been working on for the last few months, an online catalogue of underground cultural events in the city of Berlin: Experimental Berlin. My best effort to date I think! For this project I’ve been using Yoshua Wuyts' excellent JavaScript framework Choo.
Tag: Open Source
Posts
read more
Maintainership of html-to-react
I’m happy to announce that I’ve taken over maintainership of the popular NPM package html-to-react, which currently has about 3600 downloads per month. This package has the ability to translate HTML markup into a React DOM structure.
An example should give you an idea of what html-to-react brings to the table:
var React = require('react');
var HtmlToReactParser = require('html-to-react').Parser;
var htmlInput = '<div><h1>Title</h1><p>A paragraph</p></div>';
var htmlToReactParser = new HtmlToReactParser();
// Turn HTML into a bona fide React component that we can integrate into our React tree
var reactComponent = htmlToReactParser.parse(htmlInput);
Posts
read more
Improving Search Result Navigation in the Chromium Developer Console
As detailed in my previous blog post on Adding Support for Regular Expression Search in the Chromium Developer Console, some months ago I set out to make it possible to search for regular expressions in the Chromium/Google Chrome developer console. The task turned out to be more complicated than I anticipated however, and I was asked by the responsible developers to write a separate patch first to improve the console’s search result navigation.
Posts
read more
Adding Support for Regular Expression Search in the Chromium Developer Console
Chromium/Google Chrome is my hands-down favourite browser for developing Web sites in, owing to its incredibly sleek developer tools. I feel right at home in its JavaScript console, for evaluating JavaScript interactively or to inspect logs from a running JavaScript application. However, the latter scenario is somewhat let down by the console’s limited search functionality. At the time of writing, the console only lets you search for plain text on a line-by-line basis. If I want to search for regular expressions, which I tend to do, maybe spanning multiple lines, I’ll have to paste the console contents into a text editor (Sublime, anyone?) and search in there.
Tag: React
Posts
read more
Maintainership of html-to-react
I’m happy to announce that I’ve taken over maintainership of the popular NPM package html-to-react, which currently has about 3600 downloads per month. This package has the ability to translate HTML markup into a React DOM structure.
An example should give you an idea of what html-to-react brings to the table:
var React = require('react');
var HtmlToReactParser = require('html-to-react').Parser;
var htmlInput = '<div><h1>Title</h1><p>A paragraph</p></div>';
var htmlToReactParser = new HtmlToReactParser();
// Turn HTML into a bona fide React component that we can integrate into our React tree
var reactComponent = htmlToReactParser.parse(htmlInput);
Posts
read more
Achieving Infinite Scrolling with React.js
As part of developing MuzHack I had to implement a method of loading search results on demand, i.e. not everything at once. I decided on the "infinite scrolling" method, which means that as seen on f.ex. Twitter, you load more content as the user scrolls down the page. This is an alternative to the more traditional pagination method, where content (e.g. search results) is partitioned into pages, and the user loads more content by explicitly navigating to another page.
Tag: Aws-Ecs
Posts
read more
Zero Downtime Docker Deployment with Amazon ECS
Earlier, I wrote about zero downtime docker deployment with Tutum. I have recently started experimenting with Amazon ECS (EC2 Container Service), which is Amazon’s offering for the orchestration of Docker containers (and thus a competitor to Tutum). I don’t have a lot of experience with ECS yet, but it looks pretty solid so far.
I found there was a real lack of documentation on how to deploy updated Docker images to Amazon, however, and was forced to do some research in order to figure out how it should be done. Through some diligent experimentation of my own with the AWS ECS CLI and not least some valuable help on the Amazon forums, I was able to come up with a script and requirements for the ECS configuration that together lead to streamlined deployment. As it turns out, you even get zero downtime deployment for free (provided that you use an elastic load balancer, mind)! It’s more magical than in the Tutum case, as ECS by default upgrades one node after the other in the background (hidden by the load balancer) so long as it is allowed to take down at least one node as required.
Tag: Docker
Posts
read more
Zero Downtime Docker Deployment with Amazon ECS
Earlier, I wrote about zero downtime docker deployment with Tutum. I have recently started experimenting with Amazon ECS (EC2 Container Service), which is Amazon’s offering for the orchestration of Docker containers (and thus a competitor to Tutum). I don’t have a lot of experience with ECS yet, but it looks pretty solid so far.
I found there was a real lack of documentation on how to deploy updated Docker images to Amazon, however, and was forced to do some research in order to figure out how it should be done. Through some diligent experimentation of my own with the AWS ECS CLI and not least some valuable help on the Amazon forums, I was able to come up with a script and requirements for the ECS configuration that together lead to streamlined deployment. As it turns out, you even get zero downtime deployment for free (provided that you use an elastic load balancer, mind)! It’s more magical than in the Tutum case, as ECS by default upgrades one node after the other in the background (hidden by the load balancer) so long as it is allowed to take down at least one node as required.
Posts
read more
Zero Downtime Docker Deployment with Tutum
In this post I will detail how to achieve (almost) zero downtime deployment of Docker containers with the Tutum Docker hosting service. Tutum is a service that really simplifies deploying with Docker, and it even has special facilities for enabling zero downtime deployment, i.e. the Tutum team has a version of HAProxy that can switch seamlessly between Docker containers in tandem with Tutum’s API. There is the caveat though, that at the time of writing, there is slight downtime involved with HAProxy’s switching of containers, typically a few seconds. I have been assured though, that this will be improved upon before Tutum goes into General Availability.
Posts
read more
Using Papertrail from Docker/Tutum
In my search for a comprehensive logging solution for MuzHack that works in a Dockerized environment, more specifically Tutum, I came across Papertrail.
Papertrail is a fairly simple Web application for log aggregation, that receives log data over the Internet through the syslog protocol. As a registered user of Papertrail, you receive a syslog address that serves as your logging destination. Multiple sources (or "systems" as per Papertrail lingo) can use the same logging destination, as Papertrail will automatically discern between them (based on their hostnames). In my case, this corresponds to my staging and production deployments.
Tag: News
Posts
read more
MuzHack featured in Electronic Beats
Electronic Beats Magazine did a quick writeup on my MuzHack project. Nice that people are paying attention!
Tag: Hapi.js
Posts
read more
Uploading Files to Amazon S3 Directly from the Web Browser
Amazon S3 is at the time of writing the premier file storage service, and as such an excellent choice for storing files from your Web application. What if I were to tell you these files never need to touch your application servers though?
The thing to be aware of is that the S3 API allows for POST-ing files directly from the user’s Web browser, so with some JavaScript magic you are able to securely upload files from your client side JavaScript code directly to your application’s S3 buckets. The buckets don’t even have to be publicly writeable.
Tag: Node.js
Posts
read more
Uploading Files to Amazon S3 Directly from the Web Browser
Amazon S3 is at the time of writing the premier file storage service, and as such an excellent choice for storing files from your Web application. What if I were to tell you these files never need to touch your application servers though?
The thing to be aware of is that the S3 API allows for POST-ing files directly from the user’s Web browser, so with some JavaScript magic you are able to securely upload files from your client side JavaScript code directly to your application’s S3 buckets. The buckets don’t even have to be publicly writeable.
Tag: Markdown
Posts
read more
Stack Overflow's Markdown Editor Adapted
Stack Overflow and Markdown
Stack Overflow is a familiar, and cherished, name to many a programmer these days. No wonder, as it is nothing short of an ingenious way of finding answers to the many problems you come across as you’re writing code. Myself I can’t remember the last time I consulted a book on programming, since starting to use SO many years ago. One of the cool things about the site is that you write your questions/answers in the (now ubiquitous) Markdown language, which is a quite readable little language that translates to HTML with support for simple formatting such as italic and bold text, plus, not least, code blocks.
Tag: Muzhack
Posts
read more
MuzHack Presentation at Notam
So I gave the first presentation ever on MuzHack today, at the Norwegian sound research centre Notam. Feedback was positive and I got lots of great leads on who I should connect with further, and elsewhere I might present, both nationally and internationally.
Another presentation elsewhere in Norway might be in the works, later this year.
Posts
read more
Continuous Deployment of MuzHack with Docker on Tutum
I have recently implemented continuous deployment of my MuzHack Web application to the Docker hosting service Tutum, in both production and staging versions. I am really pleased with the smoothness of the whole process of setting it up, and the ease of day-to-day administration.
Docker Image Definition
The very first thing I had to do was to define MuzHack’s Docker image. This is done in the so-called Dockerfile. I base it off the standard Node image. Then I add the PhantomJS headless browser, since it’s required by Meteor (for SEO purposes), and convert MuzHack from a Meteor application into a Node equivalent.
Tag: Talk
Posts
read more
MuzHack Presentation at Notam
So I gave the first presentation ever on MuzHack today, at the Norwegian sound research centre Notam. Feedback was positive and I got lots of great leads on who I should connect with further, and elsewhere I might present, both nationally and internationally.
Another presentation elsewhere in Norway might be in the works, later this year.
Posts
read more
ChucKJS Talk in Berlin
Last Thursday (the 5th of February) I gave a talk on my project ChucKJS at the Berlin NodeJS meetup. It turned out to be a very positive experience, which is especially great since it was the first time I’ve given a talk at a meetup or indeed outside of internal company gatherings. Based on the number of questions I received, there appeared to be a great deal of interest in Web Audio and Emscripten in the development community. I was even a bit surprised by the amount of questions I received after, but I’ll take this as a sign that at least my talk wasn’t boring ;) I used a Prezi throughout the talk, which I’ve shared here.
Tag: Meteor
Posts
read more
Meteor: Creating Custom Reactive Data Sources
A core concept in Meteor is reactivity. Basically, this means that Meteor can re-run computational functions automatically whenever their (reactive) data sources change. Typically, this happens without your having to think about it, since you’re using an in-built reactive data source, such as database collections. A typical example of a function needing to react to a data source (e.g. a collection) changing is a template helper, which needs to produce a new value to base the template rendering on.
Posts
read more
Calling Trello API from Meteor
I just ported the Trello client API to a Meteor package, in order to be able to authorize my application before making actual API calls from the server side (let’s just avoid the hassle of cross-site scripting).
The following snippet shows my client side flow for creating a Trello board; first I authorize against Trello, then I call a Meteor server method to perform the corresponding Trello REST API call:
Session.set("isWaiting", true)
# MuzHack's Trello app key
Trello.setKey(Meteor.settings.public.trelloKey)
# Have the Trello client lib display a popup wherein the user authorizes MuzHack's read-write access
Trello.authorize({
type: "popup"
name: "MuzHack"
scope: { read: true, "write": true }
success: ->
logger.info("Trello authorization succeeded")
token = Trello.token()
Meteor.call('createTrelloBoard', inputValues.name, inputValues.desc, inputValues.org,
token, (error, result) ->
Session.set("isWaiting", false)
if error?
logger.warn("Server failed to create Trello board:", error)
notificationService.warn("Error",
"Server failed to create Trello board: #{error.reason}.")
else
logger.debug("Server was able to successfully create Trello board")
)
error: ->
logger.warn("Trello authorization failed")
Session.set("isWaiting", false)
})
Posts
read more
Uploading Resized Pictures to S3 in Meteor Application
I am facing the need to upload pictures to Amazon S3 in my Meteor application, MuzHack. The pictures must be resized before storing in S3, and there’s the option of doing this either on my server or in the client. I have elected to go with the latter for now, since it’s simple and doesn’t put load on my server.
To resize pictures client side I am using the Meteor Clientside Image Manipulation library, and to upload pictures to S3 I am using Slingshot.
Posts
read more
How to Connect to Meteor's MongoDB Instance from Python
Today I wrote a Python script in order to insert data into Meteor’s MongoDB instance, and the first question that came up was how to get hold of the connection parameters. It turns out that Meteor has a command for this purpose:
meteor mongo -U [site]
If you leave out the 'site' argument, you’ll get the URL to connect to the local MongoDB instance for the current Meteor app (relative to the directory you’re in). The output will look something like mongodb://127.0.0.1:3001/meteor. The final component of the URL is the name of the database ('meteor').
Posts
read more
How to Set Page Title Dynamically with Meteor, Iron Router and SEO
In my Meteor-based project MusitechHub, I recently had to figure out how to set page title dynamically for certain pages. I’m using Iron Router to implement routing in the application, which laid the premise for the solution.
I gathered from the #meteor channel on IRC that I could base my solution on Manuel Schoebel’s SEO package, which is able to set the current page title. Since I wasn’t able to figure out myself how to apply it, I continued by asking on Stack Overflow. Thanks to a helpful answer here, I figured out that I could use Iron Router’s onAfterAction hook to call SEO.set in order to set the title for a certain route/page:
Tag: Logs
Posts
read more
Using Papertrail from Docker/Tutum
In my search for a comprehensive logging solution for MuzHack that works in a Dockerized environment, more specifically Tutum, I came across Papertrail.
Papertrail is a fairly simple Web application for log aggregation, that receives log data over the Internet through the syslog protocol. As a registered user of Papertrail, you receive a syslog address that serves as your logging destination. Multiple sources (or "systems" as per Papertrail lingo) can use the same logging destination, as Papertrail will automatically discern between them (based on their hostnames). In my case, this corresponds to my staging and production deployments.
Tag: Tutum
Posts
read more
Using Papertrail from Docker/Tutum
In my search for a comprehensive logging solution for MuzHack that works in a Dockerized environment, more specifically Tutum, I came across Papertrail.
Papertrail is a fairly simple Web application for log aggregation, that receives log data over the Internet through the syslog protocol. As a registered user of Papertrail, you receive a syslog address that serves as your logging destination. Multiple sources (or "systems" as per Papertrail lingo) can use the same logging destination, as Papertrail will automatically discern between them (based on their hostnames). In my case, this corresponds to my staging and production deployments.
Tag: Trello
Posts
read more
Calling Trello API from Meteor
I just ported the Trello client API to a Meteor package, in order to be able to authorize my application before making actual API calls from the server side (let’s just avoid the hassle of cross-site scripting).
The following snippet shows my client side flow for creating a Trello board; first I authorize against Trello, then I call a Meteor server method to perform the corresponding Trello REST API call:
Session.set("isWaiting", true)
# MuzHack's Trello app key
Trello.setKey(Meteor.settings.public.trelloKey)
# Have the Trello client lib display a popup wherein the user authorizes MuzHack's read-write access
Trello.authorize({
type: "popup"
name: "MuzHack"
scope: { read: true, "write": true }
success: ->
logger.info("Trello authorization succeeded")
token = Trello.token()
Meteor.call('createTrelloBoard', inputValues.name, inputValues.desc, inputValues.org,
token, (error, result) ->
Session.set("isWaiting", false)
if error?
logger.warn("Server failed to create Trello board:", error)
notificationService.warn("Error",
"Server failed to create Trello board: #{error.reason}.")
else
logger.debug("Server was able to successfully create Trello board")
)
error: ->
logger.warn("Trello authorization failed")
Session.set("isWaiting", false)
})Tag: Backup
Posts
read more
How to Back Up Discourse
I’ve recently set up a Discourse forum on DigitalOcean, and was wondering how to implement automatic backups. Turns out Discourse supports both automatic backups and uploading them to S3. Couldn’t be easier!
To save money, you might want to create a lifecycle rule on S3 to archive the backups to Glacier, which is a slower, but cost-efficient, alternative to S3.
Posts
read more
MuzHack Is in Production
For some months now I have been developing MuzHack, a platform for makers of music hardware to publish their designs. I’m pleased to say it’s finally in production! The project is in collaboration with the Norwegian music sound research center Notam. My hope is it will spark inspiration between independent hardware developers, similar to how I and so many other software developers have benefitted from GitHub.
Stay tuned for more news!
Tag: Discourse
Posts
read more
How to Back Up Discourse
I’ve recently set up a Discourse forum on DigitalOcean, and was wondering how to implement automatic backups. Turns out Discourse supports both automatic backups and uploading them to S3. Couldn’t be easier!
To save money, you might want to create a lifecycle rule on S3 to archive the backups to Glacier, which is a slower, but cost-efficient, alternative to S3.
Posts
read more
MuzHack Is in Production
For some months now I have been developing MuzHack, a platform for makers of music hardware to publish their designs. I’m pleased to say it’s finally in production! The project is in collaboration with the Norwegian music sound research center Notam. My hope is it will spark inspiration between independent hardware developers, similar to how I and so many other software developers have benefitted from GitHub.
Stay tuned for more news!
Tag: Coreos
Posts
read more
Cloud-Config File for CoreOS with 2 GB of Swap on DigitalOcean
I recently installed Discourse on a CoreOS node at DigitalOcean. Since I chose the minimum spec that Discourse can run on, 1 GB memory, I had to enable 2 GB of swap space. This is solved by configuring CoreOS with an automatic swap service, through the standard cloud-config file. My complete cloud-config file (input this into the node’s user data) looks as follows:
#cloud-config
coreos:
etcd2:
# generate a new token for each unique cluster from https://discovery.etcd.io/new?size=3
# specify the initial size of your cluster with ?size=X
discovery: https://discovery.etcd.io/
# multi-region and multi-cloud deployments need to use $public_ipv4
advertise-client-urls: http://$private_ipv4:2379,http://$private_ipv4:4001
initial-advertise-peer-urls: http://$private_ipv4:2380
# listen on both the official ports and the legacy ports
# legacy ports can be omitted if your application doesn't depend on them
listen-client-urls: http://0.0.0.0:2379,http://0.0.0.0:4001
listen-peer-urls: http://$private_ipv4:2380
units:
- name: etcd2.service
command: start
- name: fleet.service
command: start
- name: swap.service
command: start
content: |
[Unit]
Description=Turn on swap
[Service]
Type=oneshot
Environment="SWAPFILE=/2GiB.swap"
RemainAfterExit=true
ExecStartPre=/bin/bash -c "\
fallocate -l 2G $SWAPFILE && \
chmod 600 $SWAPFILE && \
chattr +C $SWAPFILE && \
mkswap $SWAPFILE && \
losetup -f $SWAPFILE"
ExecStart=/usr/bin/sh -c "/sbin/swapon $(/usr/sbin/losetup -j ${SWAPFILE} | /usr/bin/cut -d : -f 1)"
ExecStop=/usr/bin/sh -c "/sbin/swapoff $(/usr/sbin/losetup -j ${SWAPFILE} | /usr/bin/cut -d : -f 1)"
ExecStopPost=/usr/bin/sh -c "/usr/sbin/losetup -d $(/usr/sbin/losetup -j ${SWAPFILE} | /usr/bin/cut -d : -f 1)"
[Install]
WantedBy=local.target
Tag: Digitalocean
Posts
read more
Cloud-Config File for CoreOS with 2 GB of Swap on DigitalOcean
I recently installed Discourse on a CoreOS node at DigitalOcean. Since I chose the minimum spec that Discourse can run on, 1 GB memory, I had to enable 2 GB of swap space. This is solved by configuring CoreOS with an automatic swap service, through the standard cloud-config file. My complete cloud-config file (input this into the node’s user data) looks as follows:
#cloud-config
coreos:
etcd2:
# generate a new token for each unique cluster from https://discovery.etcd.io/new?size=3
# specify the initial size of your cluster with ?size=X
discovery: https://discovery.etcd.io/
# multi-region and multi-cloud deployments need to use $public_ipv4
advertise-client-urls: http://$private_ipv4:2379,http://$private_ipv4:4001
initial-advertise-peer-urls: http://$private_ipv4:2380
# listen on both the official ports and the legacy ports
# legacy ports can be omitted if your application doesn't depend on them
listen-client-urls: http://0.0.0.0:2379,http://0.0.0.0:4001
listen-peer-urls: http://$private_ipv4:2380
units:
- name: etcd2.service
command: start
- name: fleet.service
command: start
- name: swap.service
command: start
content: |
[Unit]
Description=Turn on swap
[Service]
Type=oneshot
Environment="SWAPFILE=/2GiB.swap"
RemainAfterExit=true
ExecStartPre=/bin/bash -c "\
fallocate -l 2G $SWAPFILE && \
chmod 600 $SWAPFILE && \
chattr +C $SWAPFILE && \
mkswap $SWAPFILE && \
losetup -f $SWAPFILE"
ExecStart=/usr/bin/sh -c "/sbin/swapon $(/usr/sbin/losetup -j ${SWAPFILE} | /usr/bin/cut -d : -f 1)"
ExecStop=/usr/bin/sh -c "/sbin/swapoff $(/usr/sbin/losetup -j ${SWAPFILE} | /usr/bin/cut -d : -f 1)"
ExecStopPost=/usr/bin/sh -c "/usr/sbin/losetup -d $(/usr/sbin/losetup -j ${SWAPFILE} | /usr/bin/cut -d : -f 1)"
[Install]
WantedBy=local.target
Tag: Chromium
Posts
read more
Improving Search Result Navigation in the Chromium Developer Console
As detailed in my previous blog post on Adding Support for Regular Expression Search in the Chromium Developer Console, some months ago I set out to make it possible to search for regular expressions in the Chromium/Google Chrome developer console. The task turned out to be more complicated than I anticipated however, and I was asked by the responsible developers to write a separate patch first to improve the console’s search result navigation.
Posts
read more
Adding Support for Regular Expression Search in the Chromium Developer Console
Chromium/Google Chrome is my hands-down favourite browser for developing Web sites in, owing to its incredibly sleek developer tools. I feel right at home in its JavaScript console, for evaluating JavaScript interactively or to inspect logs from a running JavaScript application. However, the latter scenario is somewhat let down by the console’s limited search functionality. At the time of writing, the console only lets you search for plain text on a line-by-line basis. If I want to search for regular expressions, which I tend to do, maybe spanning multiple lines, I’ll have to paste the console contents into a text editor (Sublime, anyone?) and search in there.
Tag: Chuckjs
Posts
read more
Building ChucK(JS) with Gradle
As part of my work to port the ChucK music programming language to JavaScript, via the Emscripten C++ to JavaScript compiler, I’ve implemented a Gradle build script for it (instead of the original Makefile). Aside from my working for Gradle, I think it’s a great choice for this kind of polyglot project, where both native and JavaScript targets are built. ChucK is also highly cross platform (i.e. Linux, OS X, Windows), which makes writing a general build script for it demanding. Gradle is a huge help here, especially after its recently gaining support for C and C++.
Posts
read more
ChucKJS Talk in Berlin
Last Thursday (the 5th of February) I gave a talk on my project ChucKJS at the Berlin NodeJS meetup. It turned out to be a very positive experience, which is especially great since it was the first time I’ve given a talk at a meetup or indeed outside of internal company gatherings. Based on the number of questions I received, there appeared to be a great deal of interest in Web Audio and Emscripten in the development community. I was even a bit surprised by the amount of questions I received after, but I’ll take this as a sign that at least my talk wasn’t boring ;) I used a Prezi throughout the talk, which I’ve shared here.
Tag: Gradle
Posts
read more
Building ChucK(JS) with Gradle
As part of my work to port the ChucK music programming language to JavaScript, via the Emscripten C++ to JavaScript compiler, I’ve implemented a Gradle build script for it (instead of the original Makefile). Aside from my working for Gradle, I think it’s a great choice for this kind of polyglot project, where both native and JavaScript targets are built. ChucK is also highly cross platform (i.e. Linux, OS X, Windows), which makes writing a general build script for it demanding. Gradle is a huge help here, especially after its recently gaining support for C and C++.
Tag: Mercury
Posts
read more
How to Access Real DOM Nodes with Mercury/Virtual-DOM, Part 2
In the time since my first post on accessing non-virtual DOM nodes with Mercury / virtual-dom, I’ve learnt that my approach wasn’t as sound as I initially thought. The creator of Mercury, Jake Verbaten, let me know that virtual-dom hooks should only modify node attributes, otherwise the behaviour will be undefined ("innerHTML in hooks breaks the tree indexing that virtual-dom is using").
Instead, I learnt, one should use Mercury Widgets to render directly to the DOM. These aren’t subject to the same restrictions, so it turns out I should’ve been writing widgets instead of hooks.
Posts
read more
How to Access Real DOM Nodes with Mercury/virtual-dom
At work, we are using the Mercury JavaScript UI library, which is a more functional alternative to React (at least this is my understanding of it). It is also highly modular, in that it’s simply composed from several independent libraries (such as virtual-dom).
Like React, Mercury hides the browser DOM behind a virtual model, to improve performance. However, this can cause problems in case you need real access to the DOM. For example, a 3rd party library such as the popular spin.js may require changing the DOM directly, and consequently, the virtual DOM will not suffice.
Tag: Mongodb
Posts
read more
How to Connect to Meteor's MongoDB Instance from Python
Today I wrote a Python script in order to insert data into Meteor’s MongoDB instance, and the first question that came up was how to get hold of the connection parameters. It turns out that Meteor has a command for this purpose:
meteor mongo -U [site]
If you leave out the 'site' argument, you’ll get the URL to connect to the local MongoDB instance for the current Meteor app (relative to the directory you’re in). The output will look something like mongodb://127.0.0.1:3001/meteor. The final component of the URL is the name of the database ('meteor').
Tag: Python
Posts
read more
How to Connect to Meteor's MongoDB Instance from Python
Today I wrote a Python script in order to insert data into Meteor’s MongoDB instance, and the first question that came up was how to get hold of the connection parameters. It turns out that Meteor has a command for this purpose:
meteor mongo -U [site]
If you leave out the 'site' argument, you’ll get the URL to connect to the local MongoDB instance for the current Meteor app (relative to the directory you’re in). The output will look something like mongodb://127.0.0.1:3001/meteor. The final component of the URL is the name of the database ('meteor').
Tag: Seo
Posts
read more
How to Set Page Title Dynamically with Meteor, Iron Router and SEO
In my Meteor-based project MusitechHub, I recently had to figure out how to set page title dynamically for certain pages. I’m using Iron Router to implement routing in the application, which laid the premise for the solution.
I gathered from the #meteor channel on IRC that I could base my solution on Manuel Schoebel’s SEO package, which is able to set the current page title. Since I wasn’t able to figure out myself how to apply it, I continued by asking on Stack Overflow. Thanks to a helpful answer here, I figured out that I could use Iron Router’s onAfterAction hook to call SEO.set in order to set the title for a certain route/page: