Zero Downtime Docker Deployment with Tutum
In this post I will detail how to achieve (almost) zero downtime deployment of Docker containers with the Tutum Docker hosting service. Tutum is a service that really simplifies deploying with Docker, and it even has special facilities for enabling zero downtime deployment, i.e. the Tutum team has a version of HAProxy that can switch seamlessly between Docker containers in tandem with Tutum’s API. There is the caveat though, that at the time of writing, there is slight downtime involved with HAProxy’s switching of containers, typically a few seconds. I have been assured though, that this will be improved upon before Tutum goes into General Availability.
MuzHack - Members Now Able to Advertise Workshops
I am pleased to announce that MuzHack members are now able to inform of their availability for workshops, which to me goes hand in hand with publishing open music hardware, as it allows makers to connect with their audience (and vice versa). It should also allow for more efficient (and enjoyable) sharing of knowledge and skills, as would-be makers get the chance to learn from the experts, and socialize with other enthusiasts.
Help Functionality Added to MuzHack's Markdown Editors
The Markdown editors in MuzHack are now sporting a help button, to display documentation about the supported Markdown syntax. Early user feedback suggested this was a much desired feature, as many users aren’t familiar with the Markdown syntax.
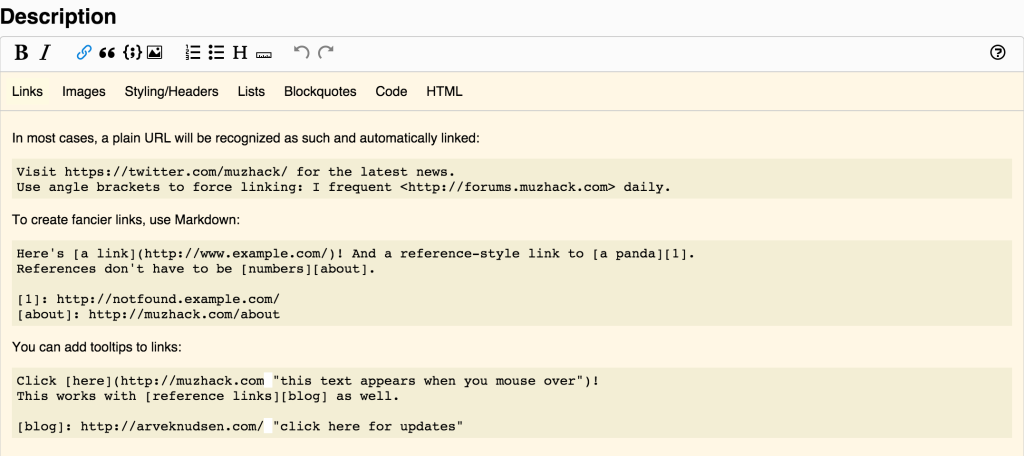
Stack Overflow's Markdown Editor Adapted
Stack Overflow and Markdown
Stack Overflow is a familiar, and cherished, name to many a programmer these days. No wonder, as it is nothing short of an ingenious way of finding answers to the many problems you come across as you’re writing code. Myself I can’t remember the last time I consulted a book on programming, since starting to use SO many years ago. One of the cool things about the site is that you write your questions/answers in the (now ubiquitous) Markdown language, which is a quite readable little language that translates to HTML with support for simple formatting such as italic and bold text, plus, not least, code blocks.
MuzHack Presentation at Notam
So I gave the first presentation ever on MuzHack today, at the Norwegian sound research centre Notam. Feedback was positive and I got lots of great leads on who I should connect with further, and elsewhere I might present, both nationally and internationally.
Another presentation elsewhere in Norway might be in the works, later this year.
Meteor: Creating Custom Reactive Data Sources
A core concept in Meteor is reactivity. Basically, this means that Meteor can re-run computational functions automatically whenever their (reactive) data sources change. Typically, this happens without your having to think about it, since you’re using an in-built reactive data source, such as database collections. A typical example of a function needing to react to a data source (e.g. a collection) changing is a template helper, which needs to produce a new value to base the template rendering on.
Using Papertrail from Docker/Tutum
In my search for a comprehensive logging solution for MuzHack that works in a Dockerized environment, more specifically Tutum, I came across Papertrail.
Papertrail is a fairly simple Web application for log aggregation, that receives log data over the Internet through the syslog protocol. As a registered user of Papertrail, you receive a syslog address that serves as your logging destination. Multiple sources (or "systems" as per Papertrail lingo) can use the same logging destination, as Papertrail will automatically discern between them (based on their hostnames). In my case, this corresponds to my staging and production deployments.
Calling Trello API from Meteor
I just ported the Trello client API to a Meteor package, in order to be able to authorize my application before making actual API calls from the server side (let’s just avoid the hassle of cross-site scripting).
The following snippet shows my client side flow for creating a Trello board; first I authorize against Trello, then I call a Meteor server method to perform the corresponding Trello REST API call:
Session.set("isWaiting", true)
# MuzHack's Trello app key
Trello.setKey(Meteor.settings.public.trelloKey)
# Have the Trello client lib display a popup wherein the user authorizes MuzHack's read-write access
Trello.authorize({
type: "popup"
name: "MuzHack"
scope: { read: true, "write": true }
success: ->
logger.info("Trello authorization succeeded")
token = Trello.token()
Meteor.call('createTrelloBoard', inputValues.name, inputValues.desc, inputValues.org,
token, (error, result) ->
Session.set("isWaiting", false)
if error?
logger.warn("Server failed to create Trello board:", error)
notificationService.warn("Error",
"Server failed to create Trello board: #{error.reason}.")
else
logger.debug("Server was able to successfully create Trello board")
)
error: ->
logger.warn("Trello authorization failed")
Session.set("isWaiting", false)
})How to Back Up Discourse
I’ve recently set up a Discourse forum on DigitalOcean, and was wondering how to implement automatic backups. Turns out Discourse supports both automatic backups and uploading them to S3. Couldn’t be easier!
To save money, you might want to create a lifecycle rule on S3 to archive the backups to Glacier, which is a slower, but cost-efficient, alternative to S3.
Cloud-Config File for CoreOS with 2 GB of Swap on DigitalOcean
I recently installed Discourse on a CoreOS node at DigitalOcean. Since I chose the minimum spec that Discourse can run on, 1 GB memory, I had to enable 2 GB of swap space. This is solved by configuring CoreOS with an automatic swap service, through the standard cloud-config file. My complete cloud-config file (input this into the node’s user data) looks as follows:
#cloud-config
coreos:
etcd2:
# generate a new token for each unique cluster from https://discovery.etcd.io/new?size=3
# specify the initial size of your cluster with ?size=X
discovery: https://discovery.etcd.io/
# multi-region and multi-cloud deployments need to use $public_ipv4
advertise-client-urls: http://$private_ipv4:2379,http://$private_ipv4:4001
initial-advertise-peer-urls: http://$private_ipv4:2380
# listen on both the official ports and the legacy ports
# legacy ports can be omitted if your application doesn't depend on them
listen-client-urls: http://0.0.0.0:2379,http://0.0.0.0:4001
listen-peer-urls: http://$private_ipv4:2380
units:
- name: etcd2.service
command: start
- name: fleet.service
command: start
- name: swap.service
command: start
content: |
[Unit]
Description=Turn on swap
[Service]
Type=oneshot
Environment="SWAPFILE=/2GiB.swap"
RemainAfterExit=true
ExecStartPre=/bin/bash -c "\
fallocate -l 2G $SWAPFILE && \
chmod 600 $SWAPFILE && \
chattr +C $SWAPFILE && \
mkswap $SWAPFILE && \
losetup -f $SWAPFILE"
ExecStart=/usr/bin/sh -c "/sbin/swapon $(/usr/sbin/losetup -j ${SWAPFILE} | /usr/bin/cut -d : -f 1)"
ExecStop=/usr/bin/sh -c "/sbin/swapoff $(/usr/sbin/losetup -j ${SWAPFILE} | /usr/bin/cut -d : -f 1)"
ExecStopPost=/usr/bin/sh -c "/usr/sbin/losetup -d $(/usr/sbin/losetup -j ${SWAPFILE} | /usr/bin/cut -d : -f 1)"
[Install]
WantedBy=local.target